
No que concerne à performance de banco de dados Oracle, a Time Model é uma das ferramentas disponíveis que podemos utilizar durantes nossas investigações. O objetivo desse artigo é expor o conceito básico dela, de modo que possamos praticar o seu uso nos artigos posteriores.
Quando nosso banco de dados está disponível, e não há nenhuma requisição da camada cliente para o banco, dizemos que o mesmo está no estado “Iddle”. Obviamente, internamente o banco está operando através dos seus processos de background, mas do ponto de vista do usuário final, ele não está fazendo nada. Esse estado é registrado no dicionário de dados com uma classe de evento chamada “Iddle waiting”, que significa que o banco está aguardando requisições da camada cliente:

Assim que o cliente manda uma requisição para o banco de dados, o mesmo começa a processá-la. Quando o banco está servindo a requisição, ele pode consumir recursos computacionais, como CPU, memória, disco, etc. O tempo que o banco investe consumindo o recurso de CPU é chamado de “CPU TIME” ou “DB CPU”.

Como esses recursos computacionais são compartilhados entre diversos outros processos no ambiente, nem sempre os mesmos estão disponíveis para o banco de dados executar o que foi delegado. Diversas vezes, o banco de dados deseja consumir um recurso, e o mesmo está ocupado, e o banco precisa esperar um tempo para que o recurso fique disponível novamente e possa ser consumido. Este tempo de espera é chamado de “DB WAITS”. E para cada tipo de recurso ocupado, há o que chamamos de “Wait Events”:
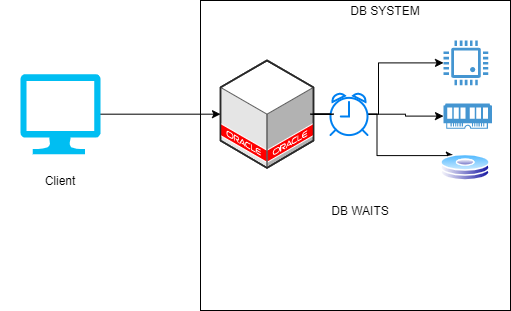
O tempo que o banco esteve engajado em atender a requisição do cliente (tanto o tempo consumindo os recursos computacionais E o tempo aguardando esses recursos) é chamado de “DB TIME”:

O conjunto de estatísticas que descrevem ONDE o “DB TIME” foi gasto dentro do banco de dados é chamado de “Time Model”. Há uma classificação desse tempo em diferentes grupos (como no exemplo abaixo) , que nos ajuda a entender onde o banco de dados precisou investir mais tempo para processar as requisições dos clientes:

Obs: Este procedimento foi criado pelo senhor Ahmed Baraka (www.ahmedbaraka.com) e foi apenas reproduzido por mim em um laboratório pessoal para fins de aprendizado.
Pingback: Describing Time Model views – Bruno Santos da Silva
Pingback: Describing Time Model views – SWIV