O CodeFish é uma ferramenta gráfica que permite a coleta de informações de backup, métricas e dados em gerais do seu ambiente Oracle (inclusive em arquitetura Exadata) para ter insumos mais precisos de Capacity Plan. É importante salientar que o seu uso é muito pontual, sendo solicitado pela própria Oracle para ajudar a analisar ambientes que serão alvos de migrações ou upgrades que exigem o apoio e respaldo do fornecedor.
O seu uso é extremamente simples, mas acho legal compartilhar o processo neste post para ajudar alguém que venha a utilizá-la no futuro. Como pré-requisitos você precisa de uma máquina Windows ou Linux, com JRE 1.8+, bancos de dados 10.2 +, licenciamento de uso do AWR, usuário privilegiado (SYSDBA). Após a coleta, é gerado uma pasta com alguns arquivos que tem uma média de 5Mb por ambiente.
Não é realizado análise “online” do ambiente, mas sim o acesso a dados históricos das bases, usando os snapshots do AWR. Também não é realizado nenhum tipo de escrita no ambiente, mas sim apenas leituras.
Após a descompactação da pasta que é disponibilizada pela Oracle, você terá os seguintes arquivos:
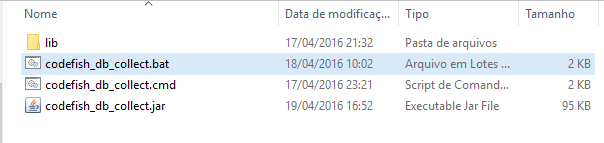
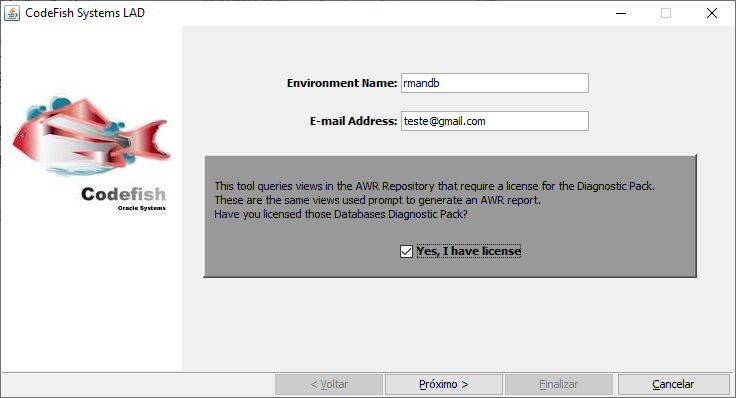
Ao executar o arquivo “codefish_db_collect.jar”, uma tela permite você digitar o nome do ambiente e um e-mail:
Preencha os dados de conexão e clique em Test and Register:
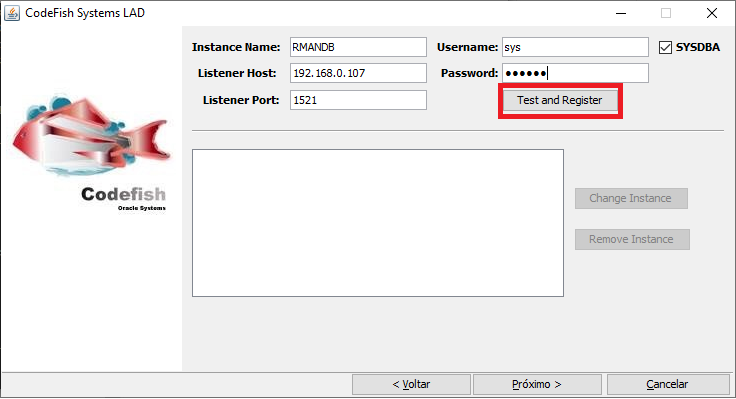
Pela experiência que tive, o campo Instance Name na verdade precisa do Service Name. A ferramenta pergunta se você quer criar um usuário para a coleta. Clique em “não”:
Desse modo, o seu banco de dados já está pronto para as próximas etapas. Clique em Próximo:
A sessão de “Segments Profiles” foi desmarcada para não precisar investir muito tempo na coleta. Mas sempre confirme com o fornecedor como ele deseja que seja feito:
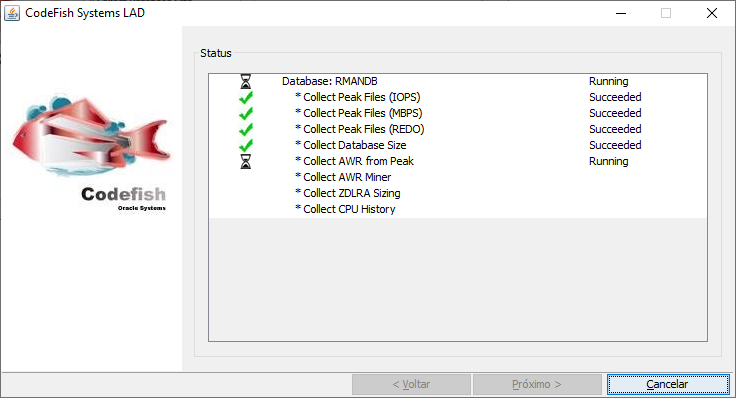
O processo inicia:
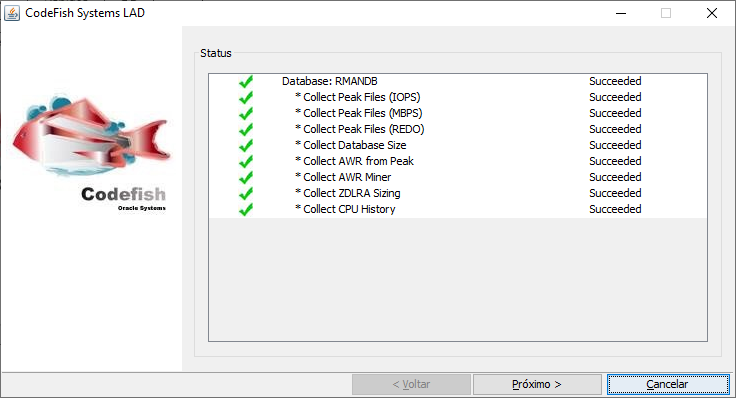
Processo finalizado:
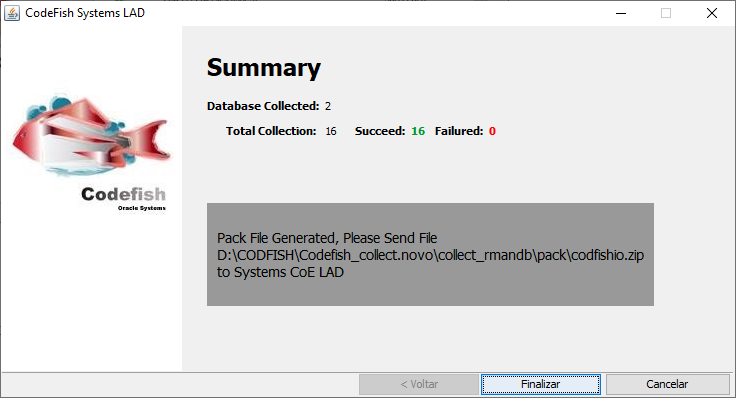
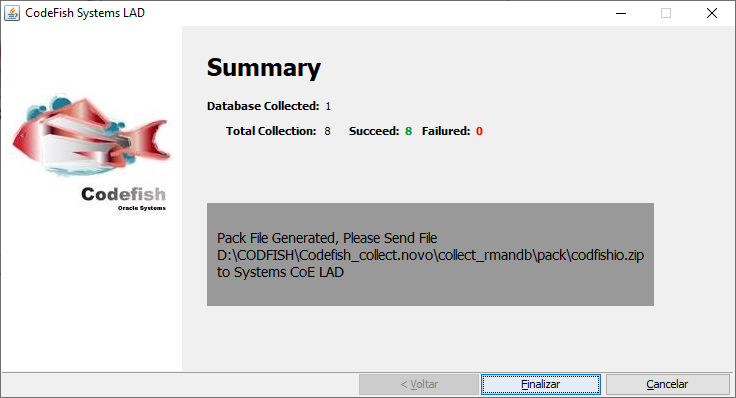
Sumário da coleta:
A pasta foi criada:
Estrutura de pastas criadas:
Como não encontrei praticamente nada na internet sobre a ferramenta, e nenhum Oracle Note no MOS, imagino que seja uma ferramenta mais restrita. Então para manter o mínimo de sigilo, não explorarei os arquivos gerados e seus conteúdos.
Mas caso você tenha um ambiente com vários bancos de dados instalados (muito comum em ambientes Exadata com vários bancos consolidados), existe a opção de fazer a coleta de forma paralela em cada banco. Basta ir adicionando os bancos na lista da ferramenta, como no exemplo abaixo:
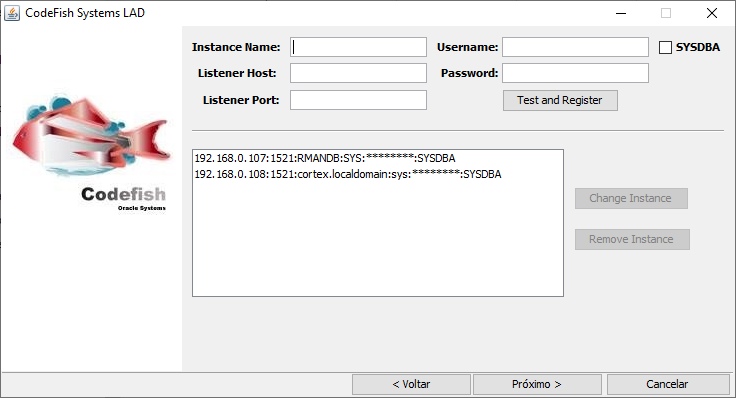
Execução sendo feita nos 2 bancos paralelamente:
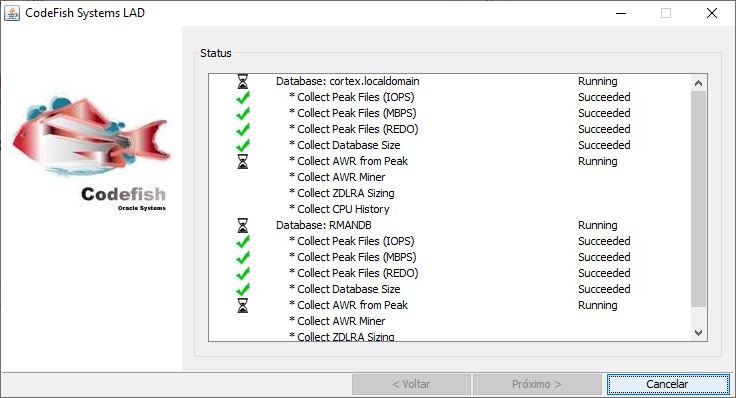
Finalizado:

Sumário: